
miscellaneous
SOCIALS




Looking into Apache Iceberg was a step we wanted to explore because I had a problem . I currently don't have our raw processed data stored persistently in a queryable format. Right now, we only have static outputs—such as monthly Parquet or CSV files sitting in object storage—but it would be useful to have a proper table format to run analytical queries against, such as:
"What were our historical totals aggregated across all time periods?"
"How did specific metrics trend across different processing snapshots?"
Among other queries that need information about the data in its entirety rather than just the discrete chunks we get from our generated files.
Why Iceberg
Iceberg is a good solution because it:
1. Persists data files (such as Parquet, ORC, or Avro) in a true table format with rich metadata
2. Lets you query all historical data in one place instead of scanning disjointed directories
3. You can run SQL queries across all time partitions seamlessly
4. Supports schema evolution—add, drop, or rename columns without breaking historical data. Migrations are still work, but significantly less painful.
5. Maintains snapshots so you can query the table exactly as it looked at any past point in time, or roll back bad writes.
Iceberg Component Overview
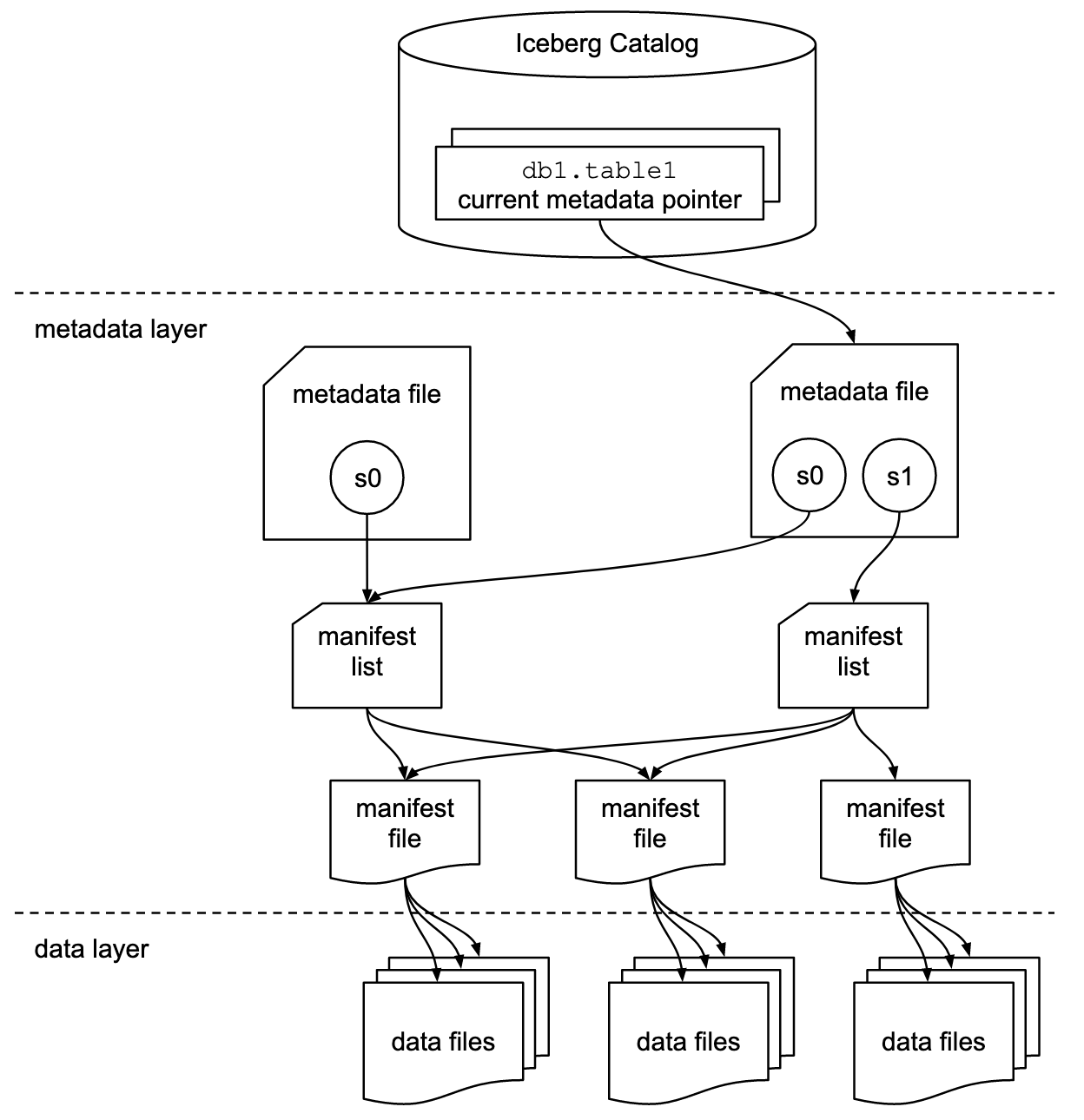
Iceberg is not something you download or install in the traditional sense; it really is just a format—a set of definitions that dictates how data files are organized, tracked, and managed, acting as a metadata layer on top of your data lake storage.
Iceberg requires three main components to function:
1. Catalog (manages table metadata and location)
2. Storage (the actual data files in the data layer, e.g., S3, HDFS, GCS)
3. Query Engine (processes the queries and plans)
Because Iceberg is so flexible, the tools you choose for Iceberg will HEAVILY depend on use case.
For our scenario, this service will primarily support internal analytics workloads—we don't foresee opening it up to external users. At most there will be one primary writer (our data pipeline) and roughly three to four readers (ad-hoc analysis, BI tools, and downstream applications).
So with one writer and a handful of readers, we do need some concurrency guarantees, but we don't need massive multi-cluster scale.
Though we want to find a solution with the **least amount of managed services**, it is equally important that these solutions are well-documented with a good ecosystem and integrate cleanly with Iceberg.
So for the choice of tooling I am balancing a few things:
- Minimal managed services
- Has ACID transactions
- Supports concurrent reads
- Integrates with Iceberg seamlessly
- Well documented with a good ecosystem & community
Choosing a Catalog: JDBC Catalog + Postgres
Iceberg by its nature is extremely unopinionated; it was designed to fit into whatever infrastructure already exists.
There are a whole host of solutions for the Catalog component. Some popular ones include the Apache Hive Metastore, then cloud providers created their own managed solutions like AWS Glue and Google BigLake, and there are more modern, complex solutions such as Nessie and Polaris that do things like `git`-style branching and version control.
Because there were so many ways to implement a catalog, it became a nightmare for tool developers to support them all, which is why theREST Catalogcame along—it was meant to be a push toward standardization.
Catalogs are essentially the sum of two components: the interface and the database. Nessie, JDBC, REST catalog and the rest can be thought of as the interface. The database is what actually stores and manages the table metadata—usually a relational DB such as Postgres or MySQL.
Initially, I considered the Hadoop Catalog because it is the most basic setup and forgoes the need to run a separate database; it uses the file system itself as the source of truth via atomic renames. However, it lacks strong ACID guarantees for writes. These atomic operations are unreliable on object stores like S3 because they only simulate atomicity via copy-and-delete, making it prone to data inconsistency in production.
We don't need all the complicated infrastructure required by Hive Metastore, nor do we need the complex features provided by something like Nessie (branching, multi-table transactions), so the next most straightforward option is to use a JDBC Catalog.
JDBC is not a separate service you interface with through a network layer—it is essentially a Direct Connection to the catalog database. It is not a separate server you log into; it is a piece of code that lives inside your query engine and gives it direct access to the metadata tables. It cuts out the middleman found in other setups where Hive or Nessie require a server process that then talks to the database.
Since we can use whatever relational database we prefer, I've gone with Postgres—it's battle-tested, familiar, and handles the lightweight metadata traffic easily.
Choosing a Catalog: Actually I changed my mind
You might realise that there is a slight issue with the JDBC Catalog with the Postgres backing and that is that into order to connect to the DB via JDBC, the two services need to be on the same network and since our use case does necessarily allow for a VPN solution, in order to access the DB via JDBC we need to open it to the internet which is not good.
Looking further into options for Iceberg and playing around with each of them respectively.
How an Iceberg Commit Works
- Write data files (Parquet/ORC/Avro).
- Write manifest files describing those data files.
- Write a new metadata file (JSON) that points at the new manifests.
- Atomically update the table’s “current metadata pointer.”
I decided to take another look at the Hadoop catalog.
- Hadoop Catalog requires atomic rename. Iceberg’s own JavaDocs state this requirement clearly. (iceberg.apache.org)
- S3‑style object stores do not have atomic rename.
Hadoop’s S3A connector emulates rename as copy + delete, which is non‑atomic and can be unsafe for commit protocols that assume atomic rename. (hadoop.apache.org)
- S3‑style object stores do not have atomic rename.
So being concerned that the Hadoop Catalog + S3/B2 can break the intended commit guarantees is valid.
What is misleading is that the previous statement may sound like Iceberg itself “lacks ACID guarantees” on object stores, this isn't the case.
The Iceberg Reliability doc says Iceberg provides atomic table commits and serializable isolation using snapshot-based metadata updates, i.e., a change is either fully committed or not visible at all, and readers always see a consistent snapshot. iceberg.apache.org.
Snapshot reads guarantee consistency of what you do read
They don't guarantee that every writer's commit survives or that the metadata is consistent.
So technically Hadoop Catalog is not fully compatible but it is something we can work with.
That being said though this option does not have strong ACID guarantees but given we have one infrequent writer and potentially 3 concurrent readers, there are some reader-side methods that we can implement in order to mitigate the potential inconsistent states such as adding a retry when it reads missing metadata or a fallback to the previous snapshot etc.
As far as strong ACID guarantees go. We have two options that I explored one is using the Iceberg REST catalog specification with something like Polaris or Gravitino or HIVE with the Hive Metastore catalog.
So for now I see 3 options:
Hive Metastore Catalog
The Hive Metastore option gives us a centralized catalog without relying on object‑store rename semantics. It stores the current metadata pointer in the metastore (typically backed by an RDBMS, I used Postgres), which makes the commit operation atomic at the catalog layer rather than the filesystem layer.
In my mind and testing it is kind of a annoying thing to navigate because it is mature but finding relevant accurate documentation might be a pain because you may need to look at multiple sources i.e. the Iceberg Doc or the Spark Doc or the HIVE documentation in order to triangulate what it is that's actually going on. But there seems to be ample resources if you're willing to dig deep.
Pros:
- Stronger commit guarantees than Hadoop Catalog on object stores.
- Well‑understood and widely supported (Spark, Trino, Flink).
- Uses a transactional metastore backend to store table metadata pointers.
Cons:
- Requires standing up Hive Metastore service and a backing database.
- Adds operational complexity.
Summary:
Hive Metastore is a mature and stable approach that avoids rename‑based failure modes, but it brings infrastructure overhead.
Iceberg REST Catalog (Polaris, Gravitino)
The REST catalog is Iceberg’s newer direction in hopes of standardizing the catalog. implements the REST catalog spec and moves the commit point into a dedicated service that can enforce atomic commit semantics without relying on object‑store rename behavior. This is a new development and the REST catalog spec is still in its infancy, the ecosystem and community is just not there and I had an extremely hard time figuring out what to do. In a lot of the Polaris and Gravitino documentation it warns that the software is still not considered stable enough for production environment so I wouldn't go down this route just now.
Pros:
- Strong commit guarantees on object stores.
- No reliance on atomic rename in S3‑compatible storage.
- API‑based and typically easier to integrate across engines.
- Can be hosted in a controlled environment without exposing an RDBMS directly.
Cons:
- A newer ecosystem than Hive (less operational history).
- Requires running a catalog service (Polaris itself).
- Some engines may require extra config or newer versions for REST support.
- Pain in the ass to setup
Summary:
Not worth it
Hadoop Catalog
The Hadoop Catalog is the most lightweight option — it keeps the catalog in the filesystem itself (the Iceberg table directory), so there is no separate service and no database required.
Pros:
- Simplest operationally — no metastore or REST service.
- Zero extra infrastructure beyond the object store.
- Works well on HDFS/local filesystems where atomic rename is reliable.
Cons:
- Requires that HDFS/local filesystems where atomic rename is reliable. S3‑style stores (including B2) do not provide atomic rename, so the commit path is not formally safe.
- Concurrent writers can lead to lost updates; even with one writer there can be transient metadata visibility issues.
Summary:
Hadoop Catalog is the lowest‑overhead option, but on object stores it is not fully compatible with strong commit semantics.
Given we only have one infrequent writer, we can likely make this work with reader‑side retries/fallbacks. This is likely the best option unless we like to suffer.
Choosing a Query Engine: Apache Spark
For the query engine, I’ve settled on Apache Spark. While there are other feature-rich query engines like Trino or Dremio, those are often built as standalone, "always-on" distributed clusters that are overkill for our current scale. They add another layer of infrastructure to manage and are generally optimized for massive, high-concurrency SQL environments. Since our primary goal is to have one reliable writer and a few internal readers, Spark is much more "portable." We can run it as a simple library or a single container without needing a massive persistent cluster.
Spark is essentially the gold standard for Iceberg; because the two projects grew up together, the integration is seamless, the documentation is extensive, and there's a robust community behind it. It gives us exactly what we need: the ability to process large historical datasets and run aggregation queries without the operational burden of deploying a full-scale query engine like Trino. It fits perfectly into our "minimal managed services" philosophy while still giving us the flexibility to handle schema evolution and historical snapshots as we scale.
Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
- Item 1
- Item 2
- Item 3
Unordered list
- Item A
- Item B
- Item C
Bold text
Emphasis
Superscript
Subscript
asdsa